Quality-Diversity Reinforcement Learning for Damage Recovery in Robotics
17 September, 2025
Overview
Legged robots operating in real-world environments is required to adapt to unexpected damage while maintaining performance. Current damage recovery approaches rely on Quality-Diversity (QD) algorithms to construct a collection of diverse behaviours, so that the robot can select a compensatory behaviour when a damage takes place. However, the original QD archives suffer from worse fitness estimates due to deterministic evaluations and present limited robustness to environmental perturbations.
Methodology
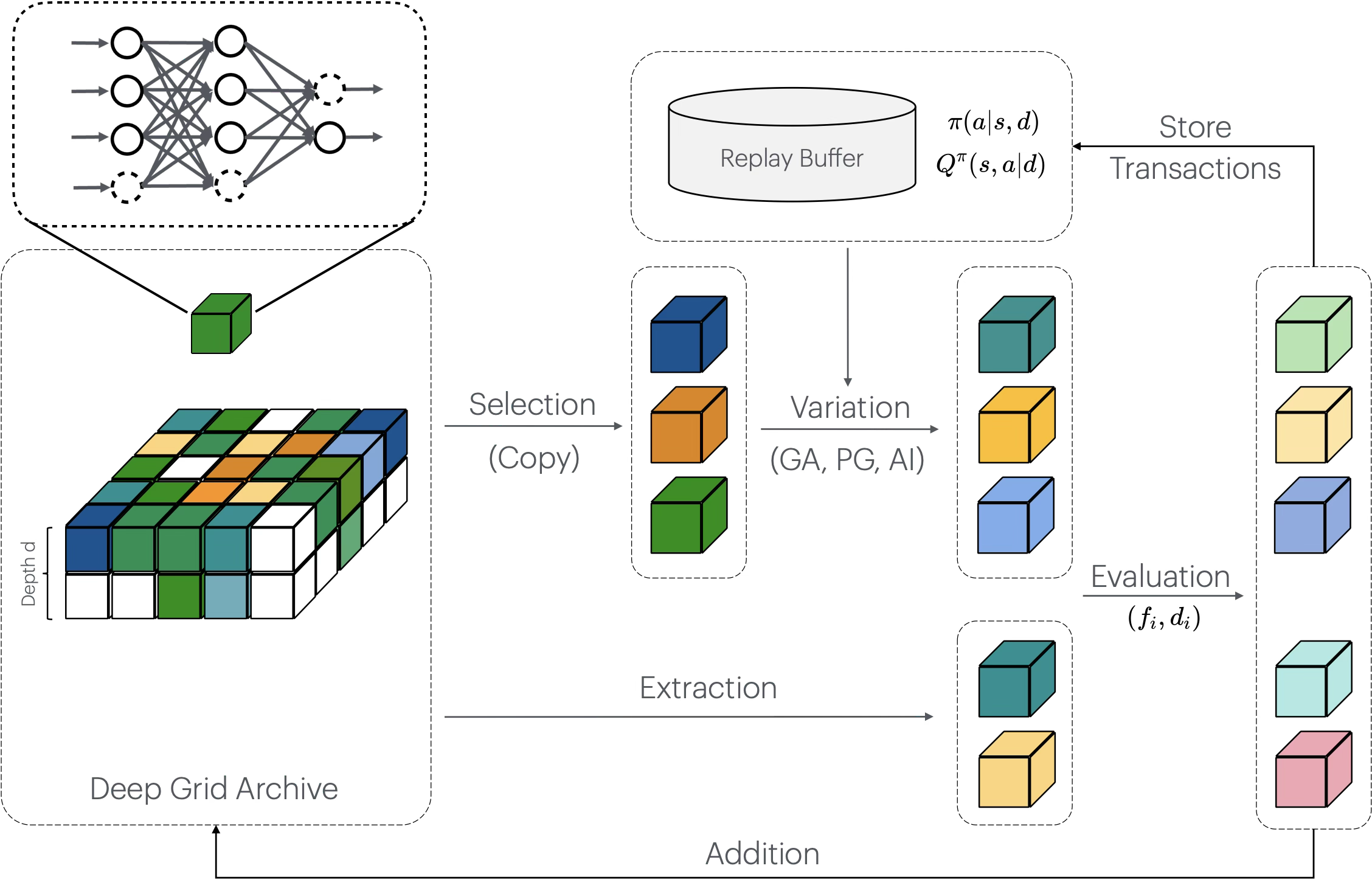
Our work carried out Regularised-Extract MAP-Elites (ReX-MAP-Elites), a framework that combines policy regularisation with uncertain QD methods, allowing us to construct an archive with solutions of more representative estimations, and whose solutions are more robust to damage.
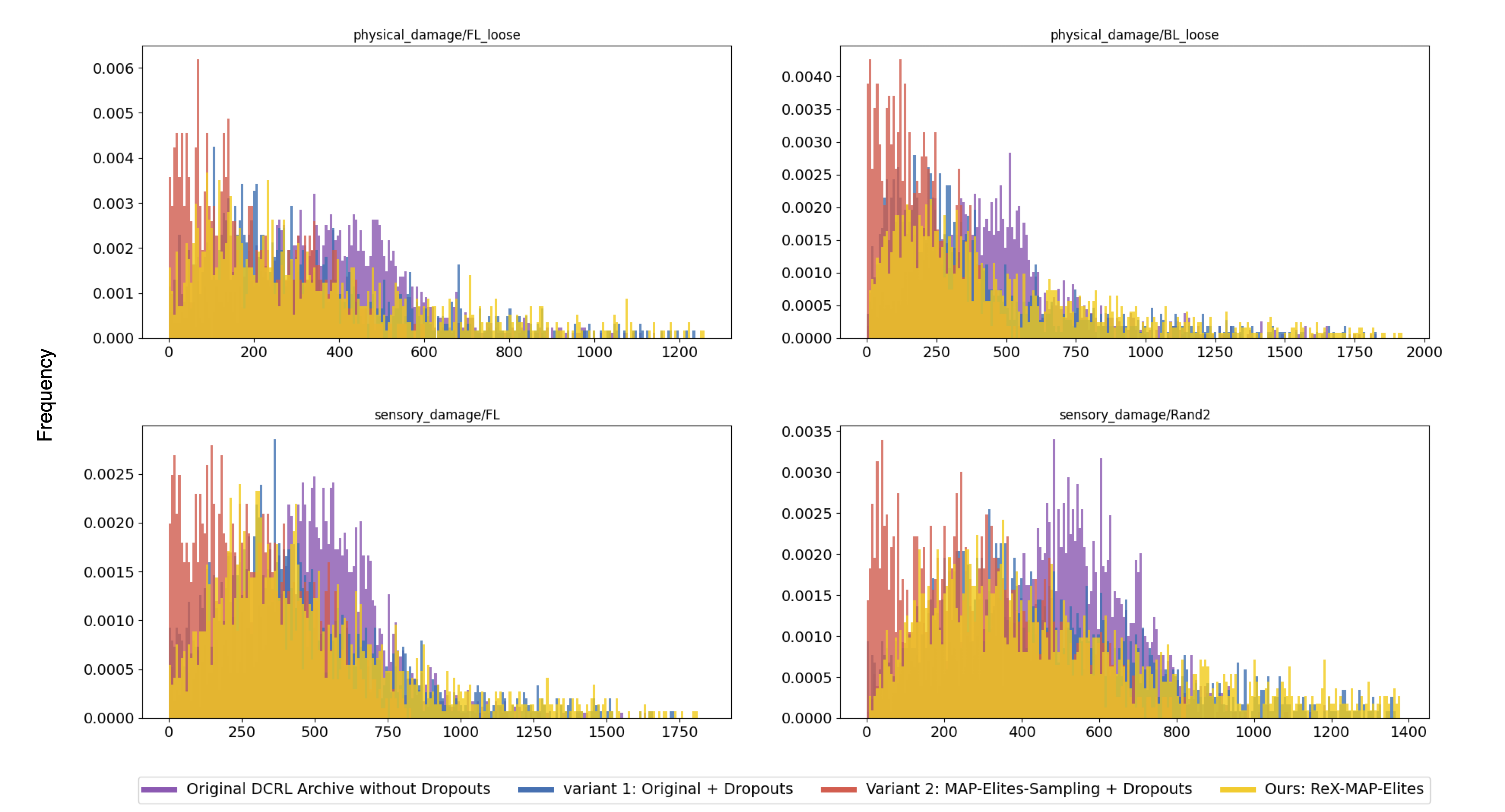
We perform evaluations on the QDax/Ant environment, where ReX-MAP-Elites outperforms other baselines by achieving a greater concentration of top-performing solutions under diverse damage configurations, and significantly better recovered performance.

Damage Recovery
ReX-MAP-Elites achieves damage recovery via Intelligent Trial and Error (ITE), where the most promising policy is selected from the archive and the estimation of fitness is updated with real fitness during rollouts. The selection-evaluation-update loop terminates when the selected policy outperforms the majority of other policies in the archive, hence a compensatory policy.
Here we visulise the walking under FL_loose, where the front-left leg experiences actuator failure, by comparing the performance of our method to previous state-of-the-art QD algorithms.
Key Takeaways
- Quality-Diversity: enables the learning of a large repertoire of both high-performing and distinct walking behaviours for robotics locomotion tasks.
- A robust Quality-Diversity Archive: Our work demonstrates that an enhancing archive with structured stochasticity and selective re-evaluation can effectively improve damage adaptation for legged robots.
- JAX Parallelisation: parallel evaluation via JAX is super efficient, as it achieves 100× speedup in policy training, especially with QD archives in large behavioural dimensions.
Sources
- The whole project is open-sourced on GitHub @ qdrl-robotics.
- Details for this work can be downloaded from here.
Great thanks to Antoine Cully and Lisa Coiffard for their the guidance and support throughout. This work is carried out under Adaptive and Intelligent Robotics Lab (AIRL).